[UK Version]
AlphaGo onder de loep
Deep Learning AlphaGo werd door het Google DeepMind team specifiek ontwikkeld om go te leren spelen. Het bedrijf werd in 2010 in Londen opgericht door Demis Hassabis, Shane Legg en Mustafa Suleyman met als missie om intelligentie te ontraadselen en de wereld een betere plaats te maken (al klinkt dat wel erg als een reclame spot). DeepMind werd destijds ondersteund door s'werelds meest iconische tech ondernemers en investeerders met een duidelijke toekomstvisie, voordat het bedrijf begin 2014 door Google werd ingelijfd –hun grootste Europese overname ooit van $400 M.

In dit blog een overzicht van de verschillende AI componenten van AlphaGo samen met details over het lesmateriaal, de leermethoden en vaardigheden van het programma. In het eerste gedeelte (Onder een klein vergrootglas) worden de belangrijkste neurale netwerk componenten globaal uitgelicht als ook hun doel en werking als onderdeel van AlphaGo. In het tweede gedeelte (Onder een groot vergrootglas) wordt in meer detail ingegaan op de eigenschappen van de convolutionele neurale netwerken waar AlphaGo op is gebaseerd.
Samen geven deze twee onderdelen in hoofdlijnen weer hoe het AI programma in staat is tot ongekende, nooit eerder vertoonde prestaties en buitengewone krachttoeren bij het spelen van go, die wonderbaarlijk en verbluffend ver uitstijgen boven de door AlphaGo geleerde, oorspronkelijke data.
Onder een klein vergrootglas
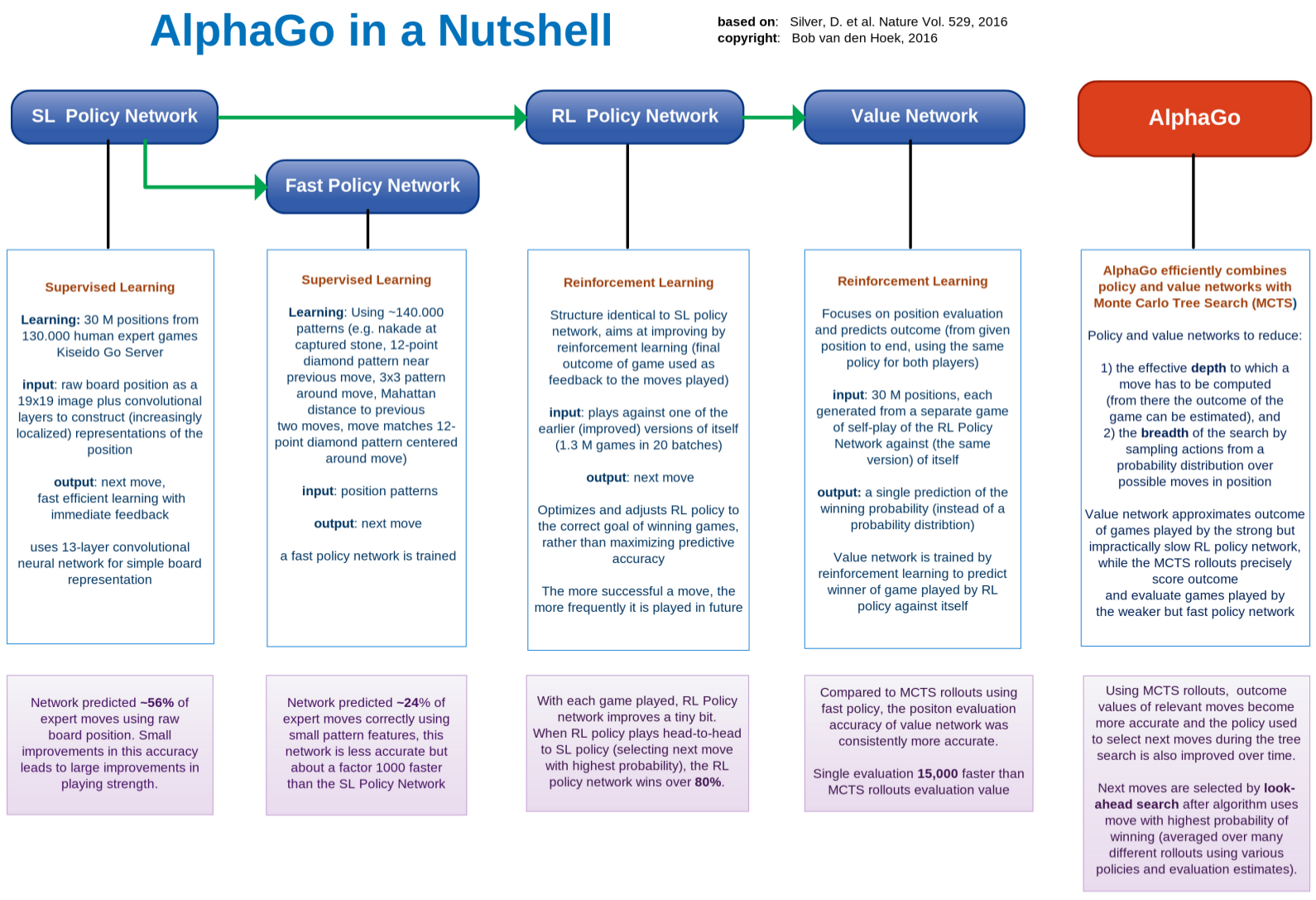
AlphaGo is gebaseerd op een vorm van kunstmatige intelligentie genaamd Deep Learning. Kortweg bestaat deze techniek uit het efficiënt leren van verbanden en patronen uit een giga hoop gegevens. Hiervoor worden verschillende complexe lagen van zelf-lerende algorithmes (neurale netwerken) gebruikt. Zo kan een neuraal netwerk, na uitgebreide training, bijvoorbeeld gezichten op foto's herkennen of gesproken zinnen correct vertalen. Eenmaal fit kan het getrainde systeem ook soortgelijke en onbekende verbanden en patronen in nieuwe data proberen te vinden.
Het bijzondere en grensverleggende van AlphaGo op AI gebied is de unieke manier waarop het programma met zeer uitgebreide en diepgaande training geleerd heeft Go-posities en patronen te herkennen en interpreteren. Hiervoor heeft het onder meer 30 miljoen posities uit 130 000 partijen van de KGS Go Server beoordeeld (met een 13-laags neuraal netwerk). Iedere laag van het netwerk krijgt daarbij een eigen taak, bijvoorbeeld het bijhouden van het aantal vrijheden. Door terugkoppeling van het eindresultaat van de partij met iedere positie heeft AlphaGo geleerd kansrijke zetten slim en efficiënt te selecteren.

Door het, na
uitgebreide training, slim beperken en selecteren van goede
vervolgzetten hoeft AlphaGo, van alle mogelijke legale zetten in
een positie, slechts nog maar enkele zetten goed door te rekenen
(rood).
Uit deze
kleine groep mogelijke voorkeurszetten selecteert AlphaGo dan de
'beste' zet, die zowel op de korte als lange termijn statistisch de
grootste kans op het winnen van de partij geeft (groen).
Dit leerprincipe is eigenlijk heel simpel en lijkt sterk op zoals we zelf ook Go leren: naarmate je meer en meer speelt geef je steeds meer waarde en voorkeur aan die zetten die in eerdere partijen succes en winst opleverden. Na training lukte het AlphaGo om 57% van de zetten van de Go-profs succesvol te reproduceren. Daarbij werd ook duidelijk dat met kleine verbeteringen in deze nauwkeurigheid onmiddelijk grote sprongen voorwaarts in speelsterkte bereikt kunnen worden (basis vervolgzet versie).
Van de basis vervolgzet versie is ook een analoge versie gemaakt die AlphaGo in staat stelt heel snel maar wel minder nauwkeurig een volgende 'beste' zet te bepalen. Hierbij maakte het programma gebruik van ~140 000 patronen om aan de hand daarvan efficiënt en snel te kunnen bepalen wat een goede vervolgzet is in een go-positie waarin één of meerdere van deze patronen voorkomt. Na uitgebreide training slaagt deze versie van AlphaGo erin om, ruwweg 1000 keer sneller dan de basis versie, ongeveer 24% van de zetten van Go-profs te reproduceren (snelle vervolgzet versie).
Met dit basis leerproces van AlphaGo is echter nog weinig nieuws onder de horizon: als je te lang doorgaat met trainen op deze manier ga je je teveel focussen op bepaalde voorkeurszetten die vaak in de bestudeerde partijen voorkomen. Het nadeel daarvan is dat je dan minder oog hebt voor andere, wellicht betere en meer kansrijke zetten voor winst.
Om dit tegen te gaan trainde een al wat volwassen versie van AlphaGo tegen willekeurig één van zijn jongere, minder wijze voorgangers. Na het spelen van telkens 64 000 partijen werd de verbeterde speelwijze van de meest volwassen AlphaGo toegevoegd aan zijn eigen groep tegenstanders. Vanaf daar kon het proces dan weer van voor af aan beginnen. Zo werden er na 20 iteraties in totaal bijna 1.3 miljoen Go-partijen gespeeld. Effectief werd het programma dus steeds sterker door veel tegen zichzelf te spelen (verbeterde vervolgzet versie).
Na deze landurige speelsessie won deze weledelgeleerde versie van AlphaGo meer dan 80% van zijn partijen tegen eerdere versies. En ook ruim 85% tegen het sterkste open source Go programma Pachi dat op dit moment als 2d amateur op KGS speelt en ~100 000 vervolg simulaties per zet berekent. Na deze trainingstage was AlphaGo in staat objectief, snel, efficiënt en nauwkeurig zetten te selecteren met een hoge winstkans.

Een ander voorbeeld van AlphaGo's vervolgzet versie: in iedere positie wordt gekeken naar alle mogelijke legale zetten.Door langdurige training heeft AlphaGo geleerd welke selectie van zetten daarvan de hoogste kans op winst van de partij bieden. En uit die selectie kiest AlphaGo dan weer de zet die het als meest veelbelovend wordt gezien door de verschillende algoritmes.
Beide voorgaande stappen waren vooral gericht op het handig selecteren van die zetten die een hoge kans op winst bieden. Maar wat als je nu in een specifieke Go-stelling grofweg wilt weten wat je kans is om een partij te winnen? Dan zou je eigenlijk alle kansrijke vervolgen moeten uitspelen en kijken welk gedeelte daarvan winst oplevert. En aangezien dat iedere keer weer mega veel rekentijd kost, trainde AlphaGo verder om dit nauwkeurig maar vooral heel snel te kunnen doen.
Bij deze training bouwt AlphaGo --bij iedere te beoordelen go-positie-- een complete verzameling partijen op (door snel op het eerste gezicht willekeurige zetten te spelen totdat de partij is afgelopen) om te zien wie er uiteindelijk zal winnen. In werkelijkheid zijn dit helemaal geen willekeurige zetten omdat het programma daarbij heel slim de snelle snelle vervolgzet versie ('policy netwerk') gebruikt om heel selectief te bepalen welke zetten de hoogste winstkans bieden.
Het zou gewoonweg te veel rekentijd kosten om de basis (of verbeterde) vervolgzet versie daarvoor in te zetten. Van de vervolgzet versie zijn dus drie versies gemaakt die qua architectuur gelijk zijn maar sterk verschillen in nauwkeurigheid en snelheid waarmee ze de volgende zet slim kunnen selecteren.
Tijdens het uitspelen van een go-positie kiest de snelle vervolgzet versie voor beide partijen snel en efficiënt de 'best' mogelijke zet. Deze efficiënte 'rollout policy' van AlphaGo is op dezelfde manier gebouwd en getraind als het basis 'policy netwerk', maar is vooral ontworpen om heel veel sneller te zijn (zo'n 1000x sneller).
Ook bij deze training van AlphaGo bleek 't weer belangrijk om proberen te generalizeren naar nieuwe posities, in plaats van teveel te leunen op al eerder voorbij gekomen en bestudeerde Go-stellingen. Daartoe speelde de volwassen versie van AlphaGo opnieuw tegen zichzelf om zo 30 miljoen posities te genereren waarbij voor iedere positie afzonderlijk de kans op het winnen van de partij werd berekend. Deze versie van AlphaGo is dus vooral gericht op het snel evalueren van de stelling (evaluatie versie).
Elk van deze versies van AlphaGo kun je een behoorlijke Go-partij laten spelen op top amateur niveau. Tegelijkertijd kun je je voorstellen dat de vervolgzet versie teveel nadruk gaat leggen op de beste zet in een bepaalde stelling terwijl de evaluatie versie voornamelijk bezig zal zijn met of een zet uiteindelijk partijwinst oplevert. En dat geeft soms heel verschillende zetten tussen deze versies (vergelijk op de korte vs. lange termijn).
Het doordachte aan AlphaGo is nu het voor de eerste keer efficiënt combineren van neurale netwerken, zowel voor het genereren van vervolgzetten als het nauwkeurig en snel evalueren van posities, met precieze doorrekening middels Monte Carlo Tree Search. MCTS op zichzelf was tot nu toe de meest toegepaste techniek bij Go-programma's maar bleek vaak te rekenintensief en onnauwkeurig om gelijk-op van een Go-prof te kunnen winnen. Mede vanwege deze belangrijke nadelen van MCTS werd gedacht dat het nog zeker een jaar of 10 zou duren voordat een computer programma een Go-prof zonder handicap op een 19x19 bord zou kunnen verslaan.
Samenvattend worden de verschillende neurale netwerken van AlphaGo na diepgaande training ingezet om zowel het aantal door te rekenen zetten als de diepte waarmee een zet wordt doorgerekend, heel slim en effectief te beperken. Bord posities in een partij worden daarna snel en nauwkeurig beoordeeld met behulp van het 'policy netwerk' voor pientere zetselectie en een 'value netwerk' voor het berekenen van de winstkans. Door uitgekiende combinatie van de drie verschillende 'policy' netwerk versies (basis, snel, en verbeterde vervolgzet versie) met zowel het 'value' netwerk (evaluatie versie) als real-time Monte Carlo Tree Search rollout doorrekening, is AlphaGo in staat heel efficient, snel en nauwkeurig met de 'beste' zet te komen die de hoogste kans op winst biedt.
Onder een groot vergrootglas
AlphaGo is gebouwd op AI methoden die in principe geschikt zijn voor algemene toepassing. Onder de motorkap maakt het programma gebruik van convolutionele (filtering en codering door transformatie) neurale netwerken die het spel en de zetten van Go-experts tot in de kleinste details na proberen te bootsen, en vervolgens sterker worden door giga veel tegen zichzelf te spelen.
In de laatste paar jaar hebben deep learning convolutionele neurale netwerken (CNN) ongekende prestaties bereikt bij het classificeren van afbeeldingen en 't herkennen van gezichten en locaties op foto's. Deze netwerken gebruiken verschillende, uitgebreide lagen van neuronen (leer-eenheden) om zodoende zelfstandig steeds meer abstracte, zeer locale en gedetailleerde representaties van een beeld te maken (zonder daarbij steeds aan het handje te hoeven worden gehouden).
Iedere netwerklaag werkt daarbij als een filter voor de aanwezigheid van bepaalde eigenschappen of patronen. Het maakt daarbij niet uit wáár in het oorspronkelijke beeld een bepaalde eigenschap of patroon aanwezig is: de filters zijn er vooral op uit om te detecteren dát het beeld deze bepaalde kenmerken heeft. Het filter wordt daarbij steeds verschoven en op verschillende plaatsen toegepast totdat de hele afbeelding onder de loep is genomen (voor grootte, verschuiving, draaihoek, kleur, bewerking, onscherpte, afwijkingen van specifieke kenmerken in de oorspronkelijke afbeelding kan het filter corrigeren, indien nodig).
Het DeepMind team heeft nu een soortgelijke netwerk architectuur toegepast bij het ontwikkelen van AlphaGo. Hierbij wordt de bordpositie door middel van een afbeelding van 19x19 bordpunten als invoer aangeboden waarna de convolutionele netwerk lagen er vervolgens een handige, compacte en nauwkeurige representatie van maken. Vervolgens kunnen deze lagen dan als krachtige filters dienst doen in iedere gopositie, voor elk specifiek patroon (of kenmerk van de positie) dat je lokaal wilt detecteren en gebruiken voor bijvoorbeeld classificatie, analyse of beoordeling van de stelling op het bord.
Door steeds kleinere gedeelten van de afbeelding van de gopositie te verwerken, kunnen de specifieke kenmerken van iedere netwerklaag met elkaar gecombineerd worden om zodoende een meer en meer gedetailleerde en onderscheidende representatie van de oorspronkelijke go-positie te distilleren.
Door dit proces steeds te herhalen voor iedere netwerk laag kunnen bij de classificatie van een stelling heel specifieke en gedetailleerde eigenschappen worden gebruikt (zoals oogvorm of aantal vrijheden) om de go-positie supernauwkeurig in meerdere, zeer specifieke categoriën onder te brengen. Het bijzondere en ongelofelijk handige hierbij is dat een gostelling zo, door slimme combinatie van verschillende filters, soms op tientallen zo niet honderden eigenschappen en patronen tegelijk, héél specifiek ingedeeld en beoordeeld kan worden. Op deze manier kun je dus heel snel en precies iedere go-stelling classificeren door eerst grof te karakteriseren in termen als invloed, gevecht in de hoek, leven-en-dood probleem, en daarna steeds kleinere onderdelen van de stelling te benoemen.
Een belangrijk voordeel van deze convolutionele netwerken is het vrijwel onafhankelijk zijn van enige voorkennis en/of menselijke bemoeienis om uiteindelijk tien duizenden, ultra gedetailleerde kenmerken van een go-stelling te leren en te classificeren. Zulke netwerken hoeven een input go-positie dus maar heel weinig voor te kauwen: het netwerk is perfect in staat om deze (soms miljoenen) ultra onderscheidende kenmerken geheel zelfstandig te leren.
Iedere laag van het netwerk krijgt daarbij een eigen taak om vooraf vastgelegde eigenschappen van de stelling te herkennen, bijvoorbeeld het bijhouden van het aantal vrijheden (atari), ladders of een 'patroon boek' van alle mogelijke 3x3 patronen. Door terugkoppeling van het eindresultaat van de partij aan iedere positie, heeft AlphaGo geleerd aan iedere mogelijke zet in een stelling winstkansen toe te kennen en om veelbelovende zetten slim en efficiënt te selecteren (zie: Onder een klein vergrootglas).

Dit is een eenvoudig voorbeeld van de architectuur van een convolutioneel neuraal netwerk (zes laags) dat onderdelen bevat van de onderliggende, soortgelijke netwerk architectuur zoals die is toegepast bij AlphaGo. Ruwweg illustreert deze architectuur de werking van de convolutionele neurale netwerken van AlphaGo: de verschillende lagen convolueren (filteren en coderen door transformatie) de oorspronkelijke 19 x 19 go-positie door detectie van steeds kleinere en abstractere go-kenmerken.
Voor AlphaGo zijn twee verschillende, complexere neurale netwerken gebruikt, ieder met hun eigen taak en verantwoordelijkheden: één netwerk dat geleerd heeft de volgende 'beste' zet te selecteren en één netwerk om de winstkans van een stelling te evalueren. Voor beide netwerken van AlphaGo geldt dat zowel de getallen die in dit voorbeeld staan, als ook het getoonde aantal en type netwerk lagen wezenlijk anders zijn.
Het 'policy' netwerk van AlphaGo tijdens de Fan Hui match gebruikte 13 lagen en 192 filters, het 'value' netwerk 15 lagen (waarbij laag 2 - 11 gelijk zijn aan die van het 'policy' netwerk). Beide netwerken hebben als input een stapel van 48 feature images van 19 x 19 bordpunten (in dit voorbeeld simpelweg weergegeven door één input image) en zijn op zodanig specifieke manier geconfigureerd dat ze hun taak zo efficiënt en nauwkeurig mogelijk kunnen uitvoeren.
Met de laatste laag classificeert het netwerk de go-positie vervolgens als een zorgvuldige optelsom van al deze specifiek gedetecteerde go-kenmerken. Door uitgebreide training kunnen vervolgens nieuwe go-posities, die nog nooit eerder door het netwerk zijn gezien, op exact dezelfde manier heel specifiek en nauwkeurig door het netwerk herkend en geclassificeerd worden.
De go-stelling in dit voorbeeld zou door het netwerk bijvoorbeeld kunnen worden geclassificeerd als: rand gevecht, aanval, ko in het centrum, met de laatste zet heeft tegenstander verlengd, tegenstander heeft twee groepen gesplitst. In werkelijkheid bevat de eindclassificering door een convolutioneel netwerk soms zelfs duizenden (of tien- of honderdduizenden) filters en kenmerken die in de oorspronkelijke data, zoals in een go-stelling in dit voorbeeld, van de partij kunnen zijn.
Waar een go-mens in een lang leven hooguit 10.000 serieuze partijen kan spelen, speelt AlphaGo honderden miljoenen partijen in een paar maanden: het vanaf nul trainen van een nieuwe versie van AlphaGo neemt ongeveer slechts 4 – 6 weken in beslag. Vervolgens is deze fenomenaal getrainde AlphaGo in staat om tienduizenden go-posities per seconde uitzonderlijk nauwkeurig door te rekenen en te beoordelen (voor de gedistribueerde versie vabn AlphaGo die op meerdere, eersteklas computers draait).
In dit blog een overzicht van de verschillende AI componenten van AlphaGo samen met details over het lesmateriaal, de leermethoden en vaardigheden van het programma.
ReplyDeleteIn het eerste gedeelte (Onder een klein vergrootglas) worden de belangrijkste neurale netwerk componenten globaal uitgelicht als ook hun doel en werking als onderdeel van AlphaGo. In het tweede gedeelte (Onder een groot vergrootglas) wordt in meer detail ingegaan op de eigenschappen van de convolutionele neurale netwerken waar AlphaGo op is gebaseerd.