Almost twenty years ago program Deep Blue from IBM for the first time defeated the then chess world champion Gari Kasparov. In a match of six games with standard tournament thinking time Deep Blue won with 3.5 - 2.5. Kasparov accused IBM of false play and demanded an immediate return match. IBM refused and announced Deep Blue's retirement.
This week pioneering news went all over the world: AI program AlphaGo from DeepMind wins five game match against ruling European Champion Fan Hui (2p). Never before a computer program defeated a Go-prof with 5-0 in formal games without handicap en 1h normal thinking time (3x30s byoyomi, 19x19, 7.5 komi, chinese rules). The most challenging and complex job until now, both for computers and artificial intelligence worldwide, thus appears to be brought to completion. That would be a huge milestone in history of mankind.
The match took place already October 5-9th 2015 as a matter of fact, behind closed doors in the Google DeepMind office in London. Not until the recent research publication, about the working of the AI program, all details of the match were shared. Playing conditions and thinking time were chosen by Fan Hui himself, preceding the match. An independent arbiter judged the validity of the moves and the proceedings of the game. Also, it was agreed that the overall match outcome would be determined exclusively by the formal game results (informal games included the result would have been 8-2 for AlphaGo).
Who had thought in 1985, when Ronald Schlemper (7d) organised the central youth Go-training in the Netherlands, that a little over 30 years later a program would be able to win a no-handicap game against a 2d prof? Or in 1987, when Robert Rehm and Peter Zandveld made a bet (for 2000 dutch florines) about whether in the year 2000 a Go-program would be able to win a nine-stone handicap game against Robert Rehm (5d)? Robert won easily from HandTalk (creator Chen, Zhixing), one of the strongest Go-programs of the world at the time, and stated that it would have been even much easier if HandTalk would have had 25 stones handicap. Or in 1989, when Mark Boon for the first time became world champion computer Go and a special training Go-program would have been really proud if it could win from a 10th kyu amateur?
The spectacular breakthrough of AlphaGo happens just a few years after Takemiya Masaki (9p) was beaten in a 4-stone handicap game by program Zen (in 2012). And Yoshio Ishida (9p) by program Crazy Stone (in 2013, also with 4 stones handicap). Since AlphaGo's strength is a least that of chinese origin Go-prof Fan Hui --who learned to play Go at age 7, became 1d professional already at age 16, and who breathes and lives Go for more than 25 years-- is the question: 'Do we have to accept the fact that artificial intelligence starts to become proficient in the game of Go?'
Has the time now really begun that the immense complex game of Go, with more possible positions than atoms in the visible universe, has been comprehended completely, is fully understood and solved now, and will not be able to offer us new challenges? Should we perhaps better find us another hobby and from today on start to be absorbed in the Japanese art of flower arrangement Ikebana?
AlphaGo in a Nutshell
AlphaGo is based on a type of artificial intelligence named Deep Learning. In brief, this is a technique for efficiently learning associations and patterns from a giga amount of data. To this end, different complex layers of self-learning algorithms (neural networks) are used. After extended training, a neural network can learn, for example, to recognize faces in images or translate spoken sentences correctly. Once fit, the trained system also can try to find similar and unknown associations and patterns in new data.
The special and ground-breaking that sets apart AlphaGo in the area of AI, is the unique manner, after very extensive and in-depth training, in which the program has learned to recognize and interpret Go-positions and patterns. For this purpose AlphaGo judged, among other things, 30 million positions from games from the KGS Go Server (with a 13-layer neural network). Each layer of the network has thereby its own task, for instance to keep track of the number of liberties. By feeding the end result of the game back to every position, AlphaGo has learned to select likely winning moves in a smart and efficient manner (see Fig. 1).
This learning process is very simple basically and rather similar to the way we learn Go ourselves: as you play more and more you give increasingly added value and preference to moves that produced success and benefit in earlier games. After training, AlphaGo managed to reproduce successfully 57% of the moves from the Go-profs. During this process it became also clear that with small improvements in this accuracy immediately great leaps forwards can be achieved in playing strength .
With the basic learning process of AlphaGo, however, there is little news yet under the horizon: if you continue to train for too long in this manner, you will focus too much on preferred moves that occur frequently in the games studied. The disadvantage of this is that you may ignore other, perhaps better and more likely winning moves.
To prevent this, a more mature version of AlphaGo trained against one of it's randomly selected younger, less wise predecessors. After playing repeatedly 64000 games in this manner, the most mature AlphaGo was submitted by addition to it's own group of opponents. From that point, the entire process started all over again. In this manner, in total ~1.3 million Go-games were played after 20 iterations. Effectively, the program thus grew from strength to strength by playing many many games against itself.

Fig. 1 By smart restriction and selection (after extensive training) of good follow-up moves from all legal moves in a position, AlphaGo needs to calculate only a few moves thoroughly (red). From this small group of preferred moves AlphaGo then selects the 'best' move that statistically, both on the short and long run, provides the highest probability of winning the game (green).
After this long-term play-session the honorary version of AlphaGo won more than 80% of the games against it's predecessor versions. And also over 85% against the strongest open source Go-program Pachi which currently plays as 2d amateur on KGS and computes ~100000 follow-up simulations per move. After this training camp AlphaGo was able to select positional moves with a high probability of winning in an objective, fast, efficient, and accurate way (policy version).
Extended Muscle Training
Both preceding steps focused in particular on smart selection of moves that provide a high probability of winning. But what if you would like to know your chances of winning the game in a specific Go-position? Then you actually would have to play out all promising follow-up moves and consider what fraction of those moves would result in a win. Since this over and over again consumes a mega amount of computing time, AlphaGo was trained further to be able to do this accurately but above all in a very fast and efficient way.
During this last muscle training it again turned out to be important to try to generalize to new positions instead of leaning to much on Go-positions seen and studied previously. For this reason, the mature version of AlphaGo once again played against itself to generate 30 million positions whereas for each individual position the probability of winning the game was calculated. This version of AlphaGo therefore is predominantly oriented on fast evaluation of the position (evaluation version).
Each of the above AlphaGo versions can play a significant Go-game on top-amateur level. At the same time, however, you can imagine that the policy version will put too much emphasis on the best move in a specific position while the evaluation version will be preoccupied with whether a move ultimately leads to winning the game. And this results to substantially different moves between those versions of AlphaGo (compare in the short vs. long run).
One of the most deliberate aspects of AlphaGo is it's ability for the first time to combine neural networks, both to generate follow-up moves and to evaluate positions, efficiently and concurrently with precise move sequence computation by means of Monte Carlo Tree Search. Until now, self-contained MCTS has been one of the most applied techniques to the programming of Go. However, MCTS often turned out to be too computation intensive and inaccurate to be able to win an even game against a Go-professional. Partly because of these important disadvantages of MCTS, experts thought it would take at least another decade before a computer program would be able to defeat a Go-prof in a no-handicap, 19x19 game.
First game Fan Hui (B) against AlphaGo
During replay of the first game of the match (see Fig. 2, Fan Hui is black) a strange feeling comes over you: AlphaGo's moves are crystal clear, with a solid and sound basis, and appear to come from an opponent who is ready to fight hard for every millimeter and has an infinitely strong wanting to win. Who sly takes into account initiative, importance, and size of the moves.
In this game, the first remarkable move of AlphaGo provides both air and influence potential to it's white, somewhat heavy and hanging group while at the same time it prevents black from an eventual attack to score some points in sente (triangle).
With the last move in the diagram (circle), AlphaGo cuts two stones thereby strongly putting the screws on black while taking the initiative. After crude counting white has a reasonable chance to win the game (komi is 7.5). In the end, AlphaGo will win the game with a narrow margin of 2.5 points and leave Fan Hui undoubtedly astonished and aghast. Very poor consolation that Fan Hui still was able to win two of his five fast, informal games (with 3x30s byoyomi thinking time) against AlphaGo.
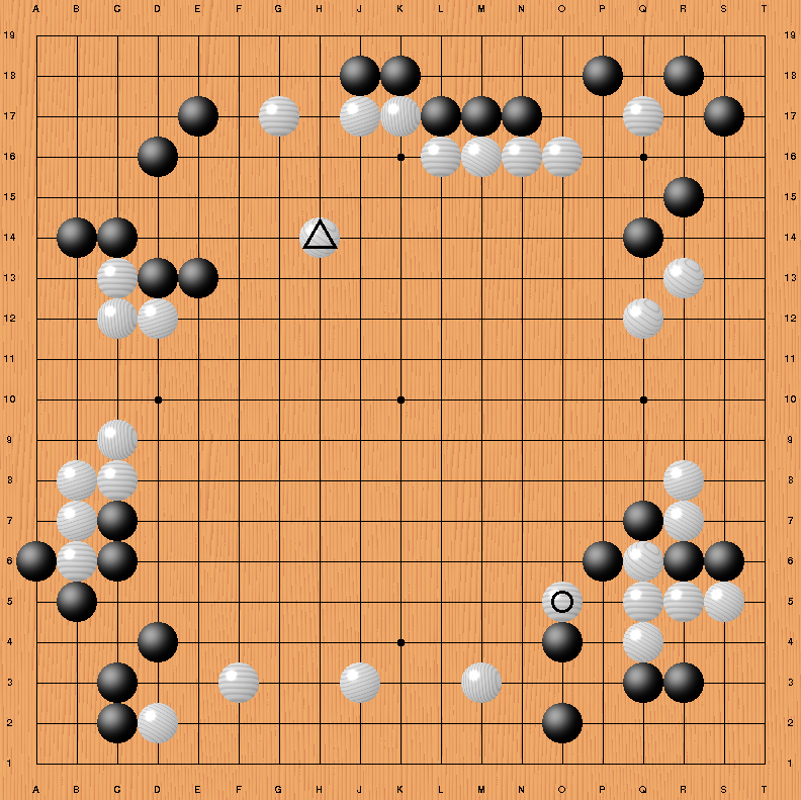
Fig. 2 Bord-position after move 62 (circle) in the first game between Fan Hui (B) and AlphaGo. The stone marked with a triangle is an example of AlphaGo's smart move selection algorithms (move 58).
Most striking characteristics AlphaGo takes into account during judgement of a position are: whether or not a move is a successful ladder breaker, how many liberties arise after playing a move, how many stones of the opponent (or of oneself) can be taken, and whether or not a move will fill it's own eyes. So, absolutely nothing about where on the board you can make territory efficiently, how you build a moyo (or destroy), when you are threatened to become surrounded (or comminuted), or how you clever kill many birds with one Go-stone.
Noteworthy enough, little to none real strategy is involved with the actions of AlphaGo. Without the giga amount of professional games and the games it played against itself, the program simply wouldn't have the slightest idea where to play (or first would have to calculate countless, very long move sequences to determine which moves would be taken into consideration).
Playing Strength of AlphaGo
Despite the considerably greater complexity of Go as compared to that of chess, AlphaGo judged thousand times less positions during the match against Fan Hui than for instance Deep Blue did during the match against Kasparov. The reason for this is that after the huge and powerful muscle training, AlphaGo restricts itself, in an ultra smart and efficient way, to just a tiny handful selection of 'best' moves. Only these moves have to be thoroughly calculated and further evaluated. So, all in all very similar to the way we try to find the 'best' move in a Go-game ourselves.
At an international computer-Go tournament (with 5 sec computing time per move) AlphaGo played also against the currently strongest commercial Go-programs Crazy Stone and Zen as well as strongest open source programs Pachi en Fuego. These programs all are based on the most efficient MCTS systems. AlphaGo did win 494 out of 495 played games. To make the games much more challenging, the other programs played in the sequel with 4 stones handicap against AlphaGo. In these games AlphaGo won also more than 77% (even 100% in case of the version of AlphaGo that was runing on multiple computers). AlphaGo turned out to be multiple dan grades stronger than all previous Go-programs.
The deep neural networks of AlphaGo for move selection and position evaluation use orders of magnitude more computation power in comparison with the traditional, exclusively MCTS based Go-programs. To be able to combine these neural networks efficiently with MCTS, AlphaGo therefore used asynchronous (multi-threaded) search missions which perform simulations on conventional CPUs and simultaneously calculate move selection and position evaluation networks on graphical processors (GPU). In this manner, the single-machine version of AlphaGo, with 48 CPUs and 8 GPUs of computation power, reaches a strength of ~2d prof.
To provide AlphaGo with even more horse-power, the people behind DeepMind developed also a version which runs on multiple computers at the same time. This distributed power-house is also the actual version of AlphaGo that was able to defeat Fan Hui with 5-0. And for that purpose AlphaGo used 1202 CPUs and 176 GPUs with according to DeepMind a strength of ~5d prof.
Near Future
Demis Hassabis, head and co-founder of Google's DeepMind, in a tweet announced Feb. 4th that AlphaGo will play a match coming March 9-15 against the strongest Go-prof of the world: Lee Sedol (9p). The 5 formal game match will be live streamed on You Tube and played in Seoul, South Korea. Lee Sedol said in a first statement he is excited to take on the challenge saying: "I am privileged to be the one to play, but I am confident I can win". The winner of the match receives $1M price money.
Depending on further improvements and development of AlphaGo over the past few months and the number of CPUs and graphical processors that will be used by the DeepMind team during the coming match, AlphaGo's strength will be reasonably close to that of Lee Sedol. Therefore, there is a great opportunity that this will be a huge thrilling match (apart from possible adaptations in AlphaGo specifically concentrated on Lee Sedol's playing style). If AlphaGo will win the match against Lee Sedol, this undoubtedly is a much greater sensation and spectacle than it was at the time Deep Blue defeated Kasparov.
Apart from his superior Go-strength, Lee Sedol has another important advantage compared to Fan Hui: at least Lee Sedol knows already what he can expect from AlphaGo. For these reasons, it is very likely Lee Sedol will win at least one of his 5 formal games against AlphaGo. But it wouldn't be surprising at all if Lee Sedol wins the match against AlphaGo with 3-2 (or 4-1). And if someone wants to bet on that account ... Deep Learning models are as good as the data you feed them.
After All
When the time will come that Go-programs like AlphaGo will generate exclusively brilliant moves and perform super humanly so that Lee Sedol even with nine stones handicap is unable to win from them?
Without intending to do any undervaluation of the incredibly valuable development and ultra smart and capable achievements of AlphaGo: in the basis the program can do little more than guiding itself on a giga memory full of Go-profs games played previously.
Surely, AlphaGo can compute moves more accurately and faster than ourselves. But whether AlphaGo before long will be able to invent and generate --itself-- new, creative, and beautifully abstract moves that, in one big blow, will allow the 'Go-flow' of the river to meander faster across the landscape?
copyright: Bob van den Hoek, Febr. 8th 2016
questions and info also to: bobvdhoek@simupro.nl
Links
http://www.nature.com/news/google-ai-algorithm-masters-ancient-game-of-go-1.19234
http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html#tables
http://www.nature.com/news/digital-intuition-1.19230
http://www.nature.com/news/go-players-react-to-computer-defeat-1.19255
https://en.wikipedia.org/wiki/Computer_Go
https://en.wikipedia.org/wiki/Deep_learning
http://googleresearch.blogspot.nl/2016/01/alphago-mastering-ancient-game-of-go.html
https://googleblog.blogspot.nl/2016/01/alphago-machine-learning-game-go.html
http://www.bbc.com/news/35501537
Silver, D. en 19 auteurs, Nature, Vol 529, 28 Jan. 2016
'GO' Magazine (NL), jaargang 38, nr 1
Neural Computing “An Introduction” R Beale & T Jackson 1990, Institute of Physics Publishing UK